Architecture
Logystera follows a three-stage architecture: Ingest → Process → Export. Each layer is built for high-throughput Vault (and other JSON) audit pipelines with strict mTLS and multi-tenant isolation.
System Overview
Applications (Vault, K8s, APIs)
↓
Forwarder Layer (Fluentd/Fluent Bit)
↓
Message Queue (RabbitMQ) ← Redis (state/cache)
↓
Consumer & Processor (YAML rules engine)
↓
Metric Registries (per-thread Prometheus)
↓
Export Layer (/metrics, /alerts, /health)
↓
Prometheus & Grafana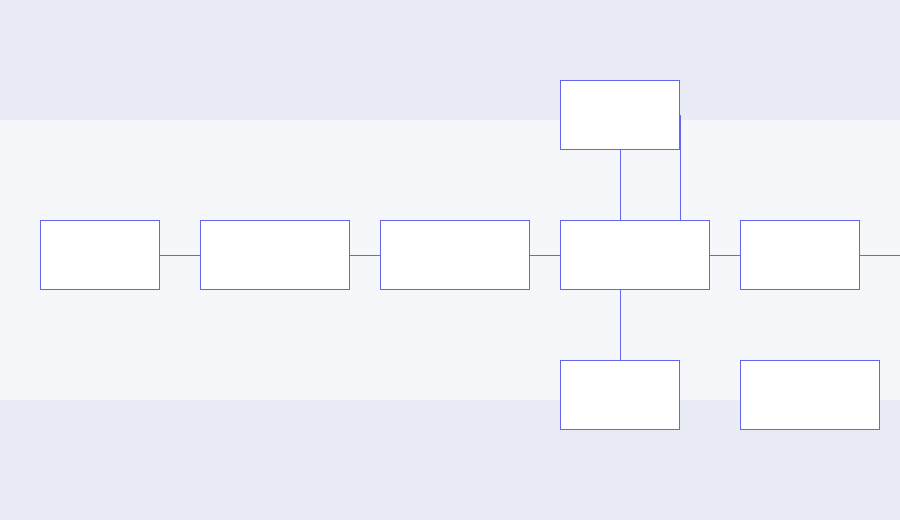
Layer 1: Ingestion
Supported Sources
- File tailing: Direct log file monitoring
- Fluentd/Fluent Bit: Normalized log forwarding with metadata injection
- RabbitMQ: Direct queue ingestion for distributed environments
- API Gateway: Cloud-hosted ingestion endpoint (launched late 2025)
Capabilities
- Automatic tenant/cluster label injection
- Multi-source consolidation
- Buffer management for traffic spikes
- Backpressure handling
Layer 2: Processing
YAML Rule Engine
Transform logs into metrics using declarative YAML configuration:
metric:
name: vault_suspicious_deletes
type: counter
when:
operation: delete
path: ^secret/production/.*
labels:
- auth.display_name
- request.pathProcessing Features
- Hot-reload: YAML changes take effect without restart
- Per-thread registries: Minimal lock contention, parallel processing
- Dynamic generation: New event types automatically create metrics
- Dry-run mode: Test rules safely on live data
- Alert bundling: Intelligent noise reduction and deduplication
Performance Characteristics
- 400+ events/sec per node
- <2 second latency from ingest to export
- Horizontal scalability across distributed environments
- Zero-downtime reloads for configuration changes
Layer 3: Export
Endpoints
- /metrics - Prometheus-compatible metrics (multiple registries supported)
- /alerts - Alert delivery status and history
- /health - System health and component status
- /stats - Processing statistics and performance metrics
Integration
- Native Prometheus scraping
- Grafana dashboard templates included
- Webhook delivery (Slack, PagerDuty, custom)
- Email alerting with retry logic
Infrastructure Dependencies
Required Components
- RabbitMQ: Message queue for log ingestion (durable, distributed)
- Redis: State management, caching, and metric storage
- Prometheus: Metric scraping and storage (customer-managed)
- Grafana: Visualization and dashboards (customer-managed)
Optional Components
- Fluentd/Fluent Bit: Log forwarding and normalization
- PKI Infrastructure: Private certificate authority for mTLS
Deployment Patterns
On-Premises (Traditional)
- All components deployed in customer infrastructure
- Full control and data sovereignty
- Air-gapped environments supported
- Private PKI for mTLS
Best for: Regulated industries, air-gapped environments, data sovereignty requirements
Cloud-Hosted via API Gateway (launched late 2025)
- Logs forwarded to Logystera API Gateway
- Managed processing infrastructure
- Faster time to value
- Reduced operational overhead
Best for: Teams wanting quick deployment, cloud-native environments, managed service preference
Hybrid
- On-premises processing for sensitive data
- Cloud-hosted for dev/test environments
- Mix deployment models per environment
Best for: Organizations with mixed compliance requirements
Security Architecture
Network Security
- mTLS: All inter-component communication encrypted
- Private PKI: Customer-controlled certificate authority (on-prem)
- No inbound connections: All data flows are push-based
- Air-gap support: No external telemetry required (on-prem)
Data Security
- No plaintext secrets stored: Only semantic metadata retained
- Role-based access control: Per-component authentication
- Audit logging: All admin actions logged
- Namespace isolation: Multi-tenant data separation
Scalability & Performance
Horizontal Scaling
- Add processor nodes to increase throughput
- Independent scaling of consumers vs. exporters
- Queue-based backpressure handling
Capacity Planning
Architecture scales from small dev environments to enterprise production:
- Small (1-5M events/day): Single node deployment
- Medium (5-25M events/day): 2-3 processor nodes, clustered infrastructure
- Large (25-100M+ events/day): 5+ processor nodes, distributed architecture
Monitoring & Observability
System Metrics
- Queue depth and lag
- Processing throughput (events/sec)
- Thread health and utilization
- Redis memory usage
- Metric cardinality tracking
Included Dashboards
- Logystera System Health: Overall platform status
- Vault General Dashboard: Cluster-wide Vault visibility
- Vault Namespace Dashboard: Per-namespace deep-dive
- Alert Dashboard: Alert delivery and suppression state
Configuration Management
Hot-Reload Support
- YAML rules changes apply immediately
- No service restart required
- Zero-downtime configuration updates
Version Control
- All configuration stored as code
- GitOps-friendly deployment
- Rollback support for rule changes